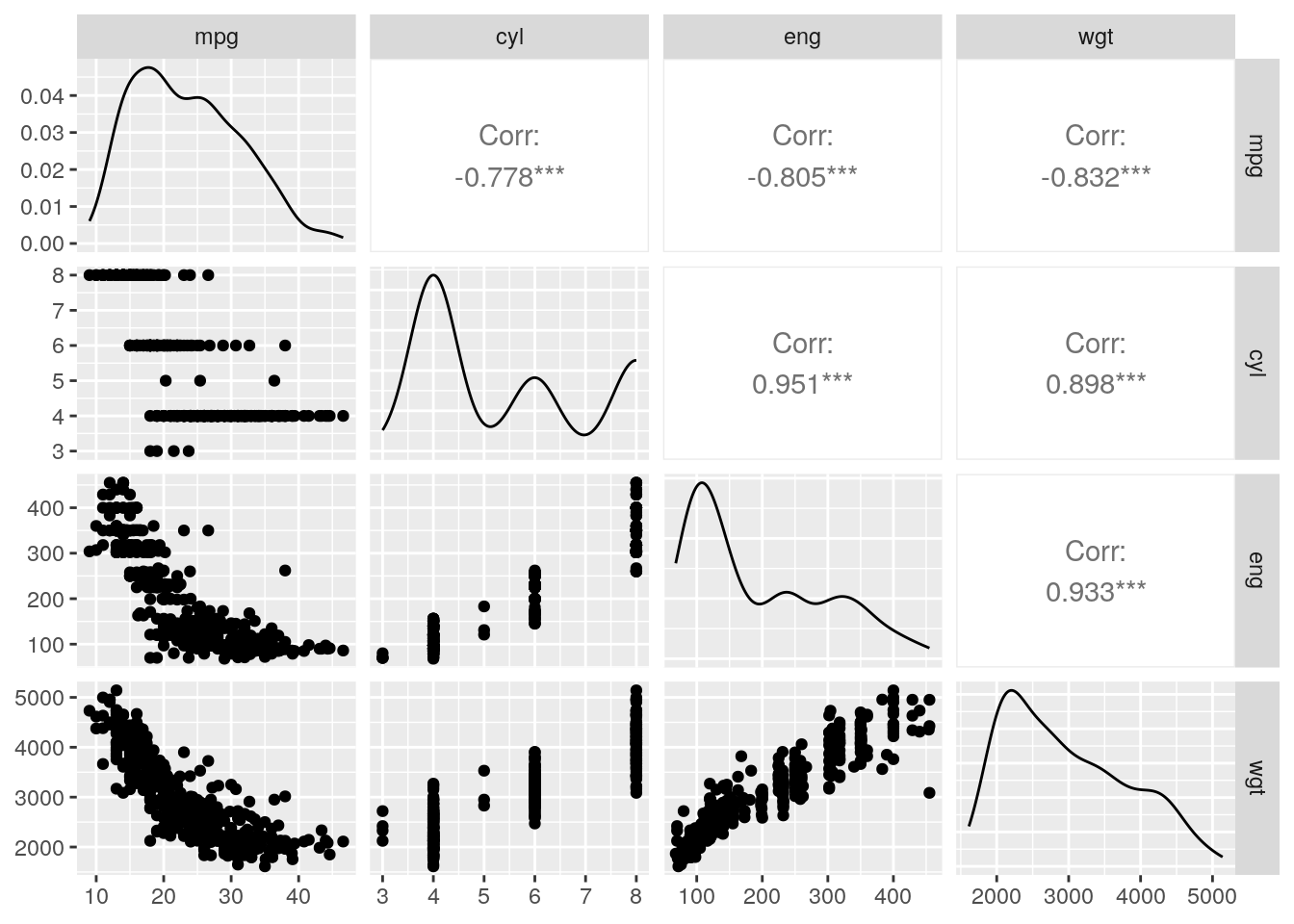
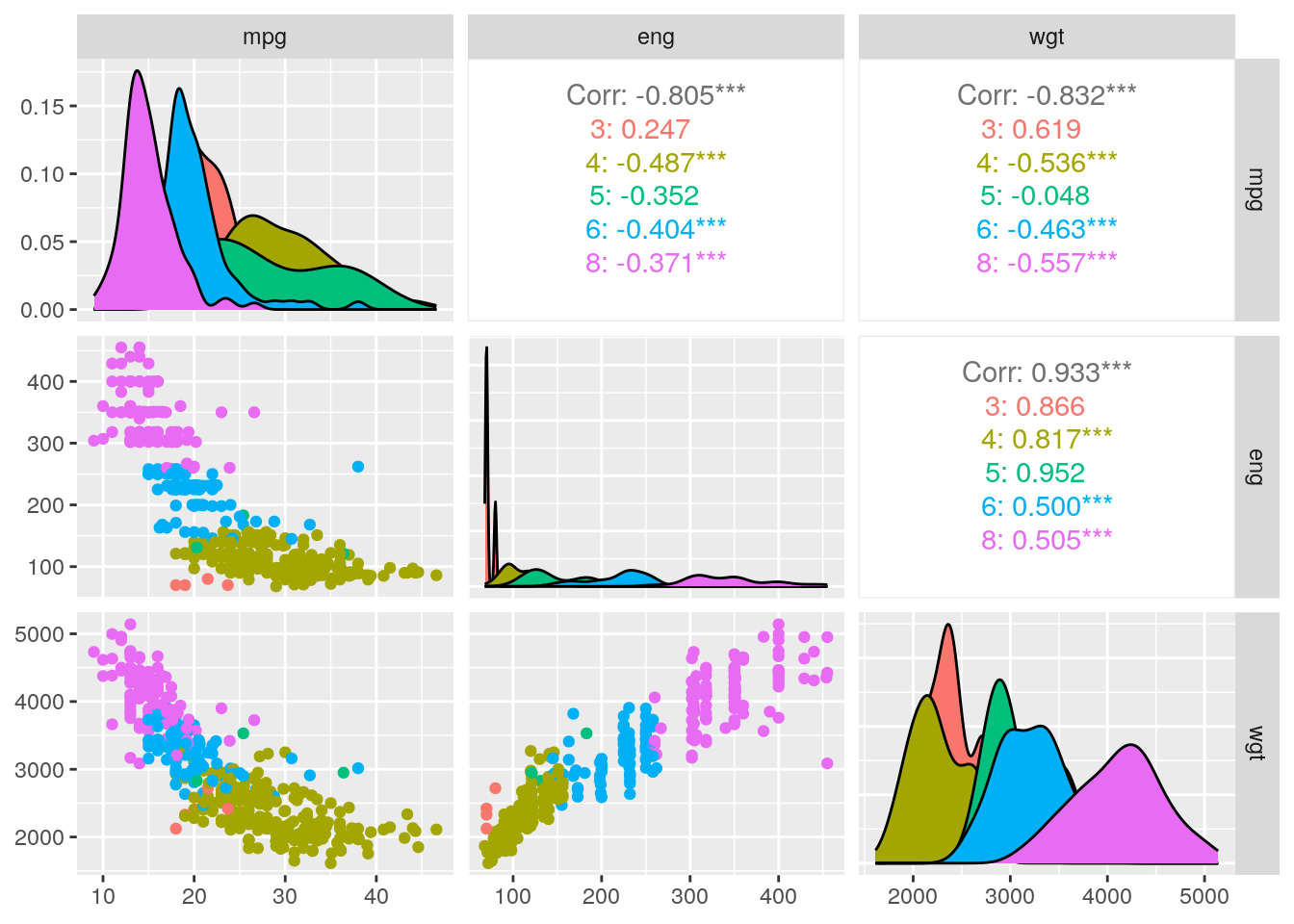
Data Exploration
The first step of using data is exploring it. I will use Stata data because it has labels, making it easy to get a sense of the data once you get the hang of how labels are dealt with in R.
Setup
Download the cars data set from here or run the code below:
Making a codebook from a Stata .dta
In Stata variables have labels, which is great because they’re more informative than variable names. In R, it can be a bit tricky to access the labels of imported dta’s, but making a code book isn’t that hard.
First, load the cars data set:
The variable labels are stored as attributes of the variables. The attributes()
function returns all attributes:
## $label
## [1] "miles per gallon"
##
## $format.stata
## [1] "%9.0g"To see only the label use:
## [1] "miles per gallon"To create a data frame with all variable labels we can apply attributes()
to all variables using map_chr() from the purrr package:
## # A tibble: 4 × 2
## var label
## <chr> <chr>
## 1 mpg miles per gallon
## 2 cyl number of cylinders
## 3 eng engine displacement in cubic inches
## 4 wgt vehicle weight in poundsTo make it slightly more useful, we can add some summary statistics.
I can apply a number of functions to a data frame using map_dbl(),
which returns a named vector:
list_of_functions <- list(mean=mean,sd=sd,min=min,max=max)
list_of_functions %>%
map_dbl(~.x(cars$mpg, na.rm = TRUE))## mean sd min max
## 23.445918 7.805007 9.000000 46.599998To do this for every column in a dataframe, I wrap the code above
in a function, and use map() to apply that function to the columns.
stats_to_tibble <- function(var,funs) {
funs %>%
map_dbl(~ifelse(is.numeric(var),.x(var,na.rm = TRUE),NA)) %>%
as_tibble_row()
}
summ_stats <-
cars %>%
map(~stats_to_tibble(.x,list_of_functions)) %>%
list_rbind()
summ_stats## # A tibble: 4 × 4
## mean sd min max
## <dbl> <dbl> <dbl> <dbl>
## 1 23.4 7.81 9 46.6
## 2 5.47 1.71 3 8
## 3 194. 105. 68 455
## 4 2978. 849. 1613 5140I can bind that with the codebook I had before to get a nice overview of all the variables in my dataset:
## # A tibble: 4 × 6
## var label mean sd min max
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 mpg miles per gallon 23.4 7.81 9 46.6
## 2 cyl number of cylinders 5.47 1.71 3 8
## 3 eng engine displacement in cubic inches 194. 105. 68 455
## 4 wgt vehicle weight in pounds 2978. 849. 1613 5140Here’s a re-usable function that add more columns, handles empty labels
(using coalesce()) and rounds the output so it’s human-readable:
create_codebook <- function(.df,stats = list(mean=mean,sd=sd,min=min,max=max,
prop_miss=prop_miss)) {
labels <- tibble(var = colnames(.df),
label = map_chr(.df,function(x) coalesce(attributes(x)$label,"")),
type = map_chr(.df, typeof))
prop_miss <- function(x,na.rm = TRUE) {
mean(is.na(x))
}
stats_to_tibble <- function(var,stats) {
map_dbl(stats,~ifelse(is.numeric(var),.x(var,na.rm = TRUE),NA)) %>%
as_tibble_row()
}
sumstats <-
.df %>%
map(~stats_to_tibble(.x,stats)) %>%
list_rbind() %>%
mutate(across(where(is.numeric),
~round(.x,2)))
bind_cols(labels,sumstats)
}
create_codebook(cars) ## # A tibble: 4 × 8
## var label type mean sd min max prop_miss
## <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 mpg miles per gallon doub… 2.35e1 7.81 9 46.6 0
## 2 cyl number of cylinders doub… 5.47e0 1.71 3 8 0
## 3 eng engine displacement in cubic… doub… 1.94e2 105. 68 455 0
## 4 wgt vehicle weight in pounds doub… 2.98e3 849. 1613 5140 0